
「Pythonでデータを加工できるのは分かった。でも、それをどうやってExcelに保存するの?」 そんな疑問に答えるのがこの記事です!
今回は、Pythonのpandasライブラリを使って、Excelファイルに書き出す(保存する)方法をやさしく解説します。
特に、文系出身のエンジニアや、Excel作業に慣れているけどPythonはこれから…という方におすすめです。たぶん。。
この記事は広告を含みます。
![]()
Pythonのインストール
Pythonのインストールや開発環境の作り方は以下をご参照ください。
to_excel()ってなに?
pandasのto_excel()は、DataFrame(表形式のデータ)をそのままExcel形式(.xlsx)で保存できるメソッドです。
df.to_excel("出力ファイル名.xlsx", index=False)
とてもシンプルですよね。
1. 実際に書き出してみよう
まずは基本的な例から。
pip install pandas openpyxl
import pandas as pd # データ作成 data = { '名前': ['田中', '鈴木', '佐藤'], '売上': [10000, 15000, 12000] } df = pd.DataFrame(data) # Excelファイルとして保存 df.to_excel('sales.xlsx', index=False)
これで、同じフォルダにsales.xlsxというExcelファイルが出力されます。
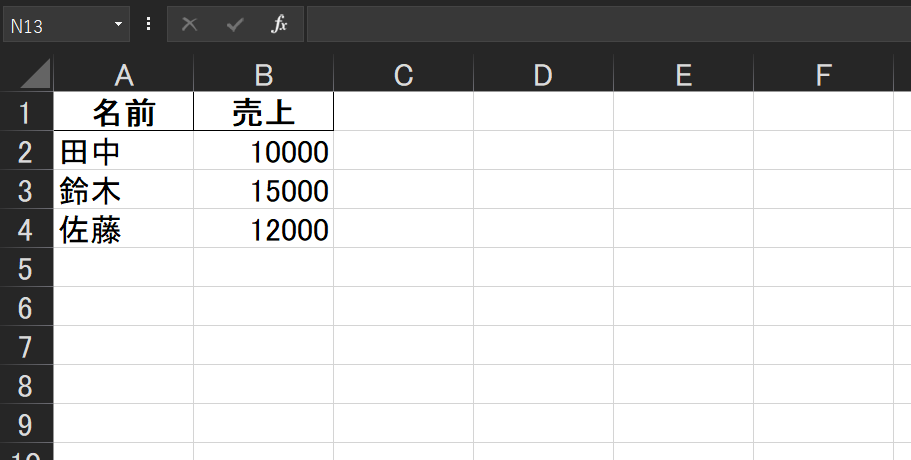
- `index=False`にすると、左端の行番号が出力されません
- ファイル名は拡張子 `.xlsx` を忘れずに
- 列名(ヘッダー)はそのままExcelの1行目になります
2. シート名を指定するには?
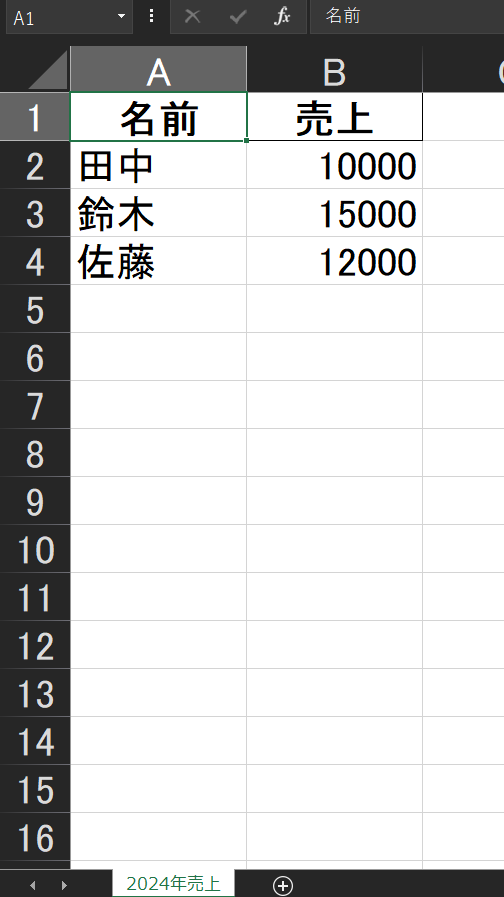
df.to_excel('sales.xlsx', sheet_name='2024年売上', index=False)
sales.xlsxの中に「2024年売上」という名前のシートが作られます。
複数のシートを書き出したい場合
複数のDataFrameを、ひとつのExcelファイルにまとめたいときはExcelWriterを使います👇
import pandas as pd # データフレーム1:1月の売上データ data_january = { '名前': ['田中', '鈴木', '佐藤'], '売上': [10000, 15000, 12000] } df1 = pd.DataFrame(data_january) # データフレーム2:2月の売上データ data_february = { '名前': ['田中', '鈴木', '佐藤'], '売上': [13000, 16000, 11000] } df2 = pd.DataFrame(data_february) # Excelファイルに複数のシートを書き出す with pd.ExcelWriter('multi_sheet.xlsx') as writer: df1.to_excel(writer, sheet_name='1月', index=False) df2.to_excel(writer, sheet_name='2月', index=False)
「月別の売上」「店舗別データ」など、実務でよくあるパターンですね。
もう、絶対にVBよりpythonですよね!!!(pythonの構文が簡単だからです。)

既存ファイルに追記できる?
pandasのto_excel()自体には「既存ファイルに追記」する機能はありません。
よくあるエラーと対処法
ImportError: Missing optional dependency 'openpyxl'
これは、Excel形式で書き出すにはopenpyxlというライブラリが必要だよ、というエラーです。pandasだけ入れてる場合に多いです。
対処法:
pip install openpyxl
コマンドプロンプトやターミナルで上記を実行すればOKです。
実務での活用例
- 集計レポートを自動で出力し、毎週保存
- 複数のCSVを1つのExcelにまとめて出力
- データ分析結果をチームと共有(Slackやメール添付用)
あとは自動でクライアントにアクセスレポート送信とかもできるかもしれないですね。
Excelで手作業 → Pythonで自動出力」に変えるだけで、 毎月・毎週のレポート作成が10倍ラクになります
関連リンク



